分析関数percentile_cont 中央値でノイズ除去
 asai
asaiというわけで前回からの続きである。
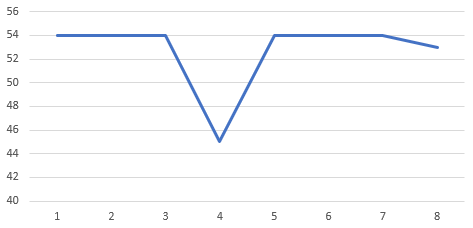
まずはデータを用意する。問題の部分を切り抜いてみた。
54 54 54 45 54 54 54 53
車速なので単位はkm/hと思われる。データの粒度は0.5秒単位。54km/hの定速で移動中な感じなのだが、途中にいきなり45km/hになっているところがある。0.5秒といった短い時間で9km/h減速して直後に戻っている。これってあきらかに「ノイズ」である。
Excelでグラフにしたらこんな感じ。
でもってこれをデータベースに取り込む。分析関数が使えないとダメなのでpostgresに取り込むことにした。
create table sensor_data ( no serial, speed integer ); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(45); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(54); insert into sensor_data(speed) values(53);
postgres=# select * from sensor_data; no | speed ----+------- 1 | 54 2 | 54 3 | 54 4 | 45 5 | 54 6 | 54 7 | 54 8 | 53 (8 行)
select percentile_cont(0.5) within group (order by speed) from sensor_data;
これで中央値は計算できた。しかしテーブル全体の中央値ではダメなので、overでウインドウを付けてみるものの、サポートしていないためか虚しくエラーになってしまった。
じゃあOracle12cでやってみるかと久しぶりにOracleを起動する。
Oracle12cでもpercentile_contとover(range between...はダメだった。avgなら行けるので移動平均なら計算できるのだが...やりたいのは中央値だしなぁ。
中央値を決定するためのspeedでのソートとウインドウを決定するためのnoでのソートの2種類のソート処理が発生するのでどうもできないみたいな感じ。ExcelのMEDIAN関数なら簡単にできるのではあるが、それだとSQLの解説にはならないし。
うーん、なんか良い逃げ道はないものか。
JSONデータに変換してみるか
select percentile_cont(0.5) within group (order by speed)
from json_to_recordset('[{"speed":54},{"speed":54},{"speed":54},{"speed":45},{"speed":54}]'::json)
as x(speed integer);
なんかうまくいきそう。
JSONデータの
'[{"speed":54},{"sp...
となっている部分をどうやって作るかだが、ウインドウ関数でleadとlagを使うかな。文字列編集する感じでやってみるか。
select no, speed,
'['
|| '{"speed":' || coalesce(lag(speed,2) over (order by no),speed) || '}'
|| ',' || '{"speed":' || coalesce(lag(speed,1) over (order by no),speed) || '}'
|| ',' || '{"speed":' || speed || '}'
|| ',' || '{"speed":' || coalesce(lead(speed,1) over (order by no),speed) || '}'
|| ',' || '{"speed":' || coalesce(lead(speed,2) over (order by no),speed) || '}'
||
']'
window_speed_data
from sensor_data
ゲゲなんか大変な感じになってしまった。
先頭レコードなどでは、前後のデータがnullになってしまう可能性があるため、coalesceでnull値はカレント行のspeedの値で代用している。
JSONデータをテーブル値に変換してpercentile_contにかければできあがりなのだがSQLでどう書けば、サブクエリか?CROSS APPLY?関数の方がいい?
関数作ってしまった方がわかりやすいかも。
というわけでJSONデータを与えると中央値を戻す関数を作成する。
create function get_median(json) returns integer as $$ declare var_median integer; begin select percentile_cont(0.5) within group (order by speed) into var_median from json_to_recordset($1) as x(speed integer); return var_median; end; $$ language 'plpgsql';
引数でもらったJSON型のデータをjson_to_recordsetでテーブル値に変換して、percentile_contで中央値を計算している。引数で渡ってくるJSONデータはlagとleadでカレント行からふたつ前と後の行からspeed列のデータを取得して文字列操作してJSONデータ化したものを想定している。
select q.no, q.speed, get_median(q.window_speed_data::json)
from (
select no, speed,
'['
|| '{"speed":' || coalesce(lag(speed,2) over (order by no),speed) || '}'
|| ',' || '{"speed":' || coalesce(lag(speed,1) over (order by no),speed) || '}'
|| ',' || '{"speed":' || speed || '}'
|| ',' || '{"speed":' || coalesce(lead(speed,1) over (order by no),speed) || '}'
|| ',' || '{"speed":' || coalesce(lead(speed,2) over (order by no),speed) || '}'
||
']'
window_speed_data
from sensor_data
) q;
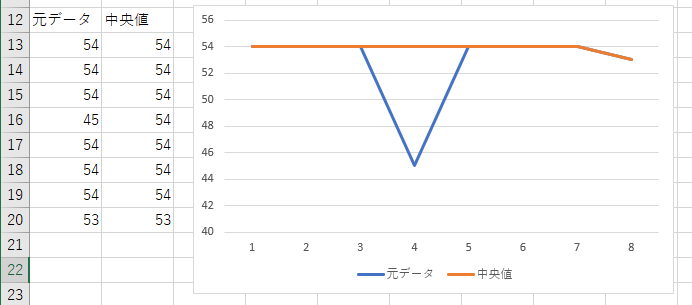
no | speed | get_median ----+-------+------------ 1 | 54 | 54 2 | 54 | 54 3 | 54 | 54 4 | 45 | 54 5 | 54 | 54 6 | 54 | 54 7 | 54 | 54 8 | 53 | 53 (8 行)
できちゃったかも。
見事に凹んだ感じの部分が平坦になっている。
分析関数percentile_cont 中央値でノイズ除去
SQL分析関数 ROW_NUMBER RANK DENSE_RANK
SQL分析関数 FIRST_VALUE LAST_VALUE NTH_VALUE LAG LEAD
SQL分析関数 PERCENT_RANK パーセンタイル
SQL分析関数 PERCENTILE_CONT PERCENTILE_DISC
SQL分析関数 CUME_DISTとCOUNT OVER SQLポケリ
WITH 再帰クエリ その2
![[改訂第4版]SQLポケットリファレンス](https://images-fe.ssl-images-amazon.com/images/I/518GTfGD0aL._SL160_.jpg "[改訂第4版]SQLポケットリファレンス")
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2017/02/18
- メディア: 単行本(ソフトカバー)

- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2019/05/16
- メディア: 単行本(ソフトカバー)
投稿者プロフィール
-
システムエンジニア
喋れる言語:日本語、C言語、SQL、JavaScript







