データベースのレプリケーションの話【リードレプリカ】
 asai
asaiえーと本日は、データベースのレプリケーションの話をしようと思う。データベースといってもRDBMSである。30年前からRDBMSは存在している。その当時もレプリケーションと呼ばれる技術は存在した。しかし、30年前は高速な通信環境が整備されていなかったからあまり積極的に使われていなかったかも。せいぜい、バックアップを自動的にやるしくみ程度の扱いだったかなぁ。だって、通信回線がISDNで128Kbpsっていう感じだからまる一日かかっても同期しないみたいな。LANでやるにしても10base-Tとかの時代なので10Mbpsしか出ない。
今や10Gbpsの時代である。うちにもあるよ10Gのスイッチ。データセンター内では100Gbpsっていうのもあるらしい。
TP-Link 10G 5ポート L2SW購入【9Gbps出た】
えーと今回はサーバー関係の話題である。N100のマザーに変えたものの、通信速度が思ったほど出なく淋しい状態だったのが前回であった。原因はPCIeスロットがx1モードで動…

でね。高速通信が可能になるとレプリケーションも便利なわけですよ。簡単に負荷分散ができる。AWSのAuroraでもリードレプリカを作成すれば負荷分散もできるし耐障害性も上がる。コストも増えるけどね。
というわけで、AWS Auroraでレプリケーションやってみたいけど、コストが倍になってしまうので、ローカル環境で実験してみたという話である。前回のNodeJSの同期、非同期の比較でイマイチな結果になったのでリベンジしたいという思いもある。
自宅で仕事をしているので、家にサーバーがある。サーバーではProxmox基盤上に各種RDBMSやファイルサーバなんかが、UbuntuやCentOSのVM上で稼働している。RDBMSはSQLの検証用。ファイルサーバはNASとして普通に使用している。CentOSはアプリケーションの開発用。DockerとかNodeJSとかが入っている。
ProxmoxにMS SQL Serverをインストール
RDBMSにおけるJSONの扱いについて調査中である。MS SQL ServerにおいてもJSONデータを扱うことができる。これは調査せねばと思ってはいたものの、WindowsマシンにSQL Serv…

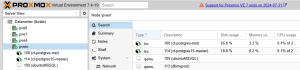
実は、Postgresについては、既にマスターとレプリカの2台構成で稼働している。
ct-postgres-mstがマスターで、ct-postgres-rr3がレプリカである。
レプリカにするには?
レプリカとして稼働させるには設定が必要である。その設定方法を見ていこう。
replication通信を許可する
まず、マスターとレプリカ間でIP通信ができないと同期することができないので、マスター側のpg_hba.confを編集して通信を許可する。ファイルの場所は色々あると思うがたいていは/etc/postgresql以下にあると思うので検索してみて欲しい。
うちの場合以下のようにした。
pg_hba.conf
# permit local network
host replication all 192.168.0.0/24 password
# Accept all IPv4 connections - CHANGE THIS!!!
#host all all 0.0.0.0/0 md5
host all all 192.168.0.0/24 md5
プライベートネットワークアドレスだけreplicationを許可。
下の1行はpsqlコマンドで外部から接続するときに必要。
マスター、レプリカの両方で設定しておく。
synchronous_standby_namesを設定する
マスター側のpostgresql.confを編集してsynchronous_standby_namesを'standby'にする。
マスター側のpostgresql.conf
# - Master Server -
# These settings are ignored on a standby server.
#synchronous_standby_names = '' # standby servers that provide sync rep
# method to choose sync standbys, number of sync standbys,
# and comma-separated list of application_name
# from standby(s); '*' = all
synchronous_standby_names = 'standby'
名前からもわかるように、スタンバイ状態のレプリカサーバーを指定するもの。ここにアプリケーション名を設定しておくことで、そのアプリケーション名でアクセスしてきたレプリカサーバーが対象になる。
hot_standbyをonにする
レプリカ側のpostgresql.confを編集してhot_standby機能をonにする。
レプリカ側のpostgresql.conf
hot_standby = on # "off" disallows queries during recovery
# (change requires restart)
pg _basebackupで初期同期にする
レプリカ側でpg_basebackupを実行してマスターのデータをレプリカ側に持ってくる。
$ rm -rf ${PGDATA}
$ pg_basebackup -R -D ${PGDATA} -h マスターのIP -U ユーザ
${PGDATA}はpostgresqlのデータが入ったディレクトリのパス。環境に合わせて変更して欲しい。空でないと作成できないエラーになるので、ファイルを削除してから持ってくる。当然ながらマスターに接続できないと持ってくることができない。
バックアップに成功すると、postgresql.auto.confが生成される。このファイルにマスターへの接続方法が記載されるので、アプリケーション名の設定を追加する。アプリケーション名は'standby'として設定したので「application_name=standby」のように追加設定する。
レプリカ側のpostgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
primary_conninfo = 'user=postgres password=パスワード channel_binding=prefer host=マスターのIP port=5432 sslmode=prefer sslcompression=0 sslsni=1 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=any
application_name=standby'
試験してみる
驚くことに「たったこれだけ」でマスターとレプリカの2台構成ができてしまう。いやいや便利。
本当にできているのか確かめてみよう。設定できたら、再起動する。立ち上がったらマスターとレプリカの両方に接続してみて欲しい。
マスター
$ psql -h 192.168.0.53 -U postgres postgres
ユーザ postgres のパスワード:
psql (13.7、サーバ 13.20 (Debian 13.20-0+deb11u1))
SSL 接続 (プロトコル: TLSv1.3、暗号化方式: TLS_AES_256_GCM_SHA384、ビット長: 256、圧縮: オフ)
"help"でヘルプを表示します。
postgres=#
レプリカ
$ psql -h 192.168.0.56 -U postgres postgres
ユーザ postgres のパスワード:
psql (13.7、サーバ 13.20 (Debian 13.20-0+deb11u1))
SSL 接続 (プロトコル: TLSv1.3、暗号化方式: TLS_AES_256_GCM_SHA384、ビット長: 256、圧縮: オフ)
"help"でヘルプを表示します。
postgres=#
何かテーブルを作成するが、ますばレプリカの方からやってみて。
レプリカ
postgres=# create table foo (a integer);
ERROR: cannot execute CREATE TABLE in a read-only transaction
レプリカはread onlyになってるので、書き込みはできない。
マスターの方で何かテーブルを作成する。
マスター
postgres=# create table foo (a integer);
CREATE TABLE
マスターはread onlyではないのでちゃんとテーブルを作成できる。マスターとレプリカは瞬時に同期されるのでレプリカ側にもテーブルが作成されている。
レプリカ
postgres=# select * from foo;
a
------------
(0 行)
おーこれは便利。
マスター側でレコードを作成してみる。
マスター
postgres=# insert into foo values(1);
INSERT 0 1
postgres=# select * from foo;
a
------------
1
(1 行)
レプリカ
postgres=# select * from foo;
a
-------------
1
(1 行)
ちゃんとできてるじゃない。
参考にしたサイト。
冗長化構成にしてみよう ~PostgreSQL ストリーミングレプリケーション編~ #RHEL - Qiita
皆さんこんにちは!haruです。 今回はPostgreSQLを使用してストリーミングレプリケーション構成をセットアップしてみます。 PostgreSQL レプリケーションの種類 ストリー…

NodeJS非同期実行のリベンジ
さて、マスターとレプリカが揃ったところで、前回やったNodeJSのクエリの非同期実行をマスターとレプリカに分散させてやってみようと思う。
ちょっとおさらいしておくと、以下のクエリを1本走らせた場合と
SELECT SUM(売上) FROM 売上結果 WHERE EXTRACT(YEAR FROM 日付) = 2024 OR EXTRACT(YEAR FROM 日付) = 2025
以下のクエリ2本に分割して非同期実行させるので
SELECT SUM(売上) FROM 売上結果 WHERE EXTRACT(YEAR FROM 日付) = 2024
SELECT SUM(売上) FROM 売上結果 WHERE EXTRACT(YEAR FROM 日付) = 2025
後者の方が少し速いことを確認している。
$ node query1.js
query: 104.378ms
$ node query2.js
query: 92.759ms
非同期実行させるDBをマスターとレプリカに分割すればより速くなるのでは?
という目論見である。
ではやってみよう。
まずは、同期で1本走らせる。
const { Pool } = require("pg");
const connectionString = 'postgres://user:pass@host:5432/postgres'; // マスターに接続
const pool = new Pool({
connectionString: connectionString,
max: 2
});
async function query(sql){
return new Promise(async function(resolve, reject) {
try {
const connect = await pool.connect();
let result = await connect.query(sql);
connect.release();
resolve(result);
}
catch(e) {
reject(e);
}
});
}
async function test() {
console.time('query');
let result = await query('SELECT SUM(売上) FROM 売上結果 WHERE EXTRACT(YEAR FROM 日付) = 2024 OR EXTRACT(YEAR FROM 日付) = 2025');
console.timeEnd('query');
pool.end();
}
test();
えーとデータは増やしてます。
次に、マスターとレプリカに分割してクエリを実行してみる。pool1とpool2を作ってそれぞれマスターとレプリカに接続するようにする。
クエリを実行する関数でどちらのプールからコネクションを持ってくるのかを引数で指定できるようにした。さらに、console.timeで別々に計測したいので、idをもらうようにする。console.timeは同時に同じ識別子が使われるとエラーになってしまうので。
const { Pool } = require("pg");
const connectionString = 'postgres://user:pass@マスターのIP:5432/postgres';
const pool1 = new Pool({
connectionString: connectionString,
max: 2
});
const connectionString2 = 'postgres://user:pass@レプリカのIP:5432/postgres';
const pool2 = new Pool({
connectionString: connectionString2,
max: 2
});
async function query(sql, pool, id){
return new Promise(async function(resolve, reject) {
try {
console.time('query'+id);
const connect = await pool.connect();
let result = await connect.query(sql);
console.timeEnd('query'+id);
connect.release();
resolve(result);
}
catch(e) {
reject(e);
}
});
}
async function test() {
console.time('total-query');
let results = await Promise.all([
query('SELECT SUM(売上) FROM 売上結果 WHERE EXTRACT(YEAR FROM 日付) = 2024',pool1,1),
query('SELECT SUM(売上) FROM 売上結果 WHERE EXTRACT(YEAR FROM 日付) = 2025',pool2,2)
]);
console.timeEnd('total-query');
pool1.end();
pool2.end();
}
test();
じゃあ、やってみよう。まずは、同期1本を流してみる。
$ node query1.js
query: 567.87ms
ふむふむ、前回よりデータを増やしているので、こんなものか。
では、次。非同期で2回のクエリを流してみる。
$ node query2.js
query2: 305.712ms
query1: 442.992ms
total-query: 443.435ms
ほほー、ちょっとだけ速くなったかも。query1よりquery2の方が先に終了している。
非同期で実行させると後に実行した方が早く終了するということが良くある。
マスターとレプリカで「同じような能力であれば良かった」のであろうが、ちょっと用意できなかった。どうしても遅い方に引っ張られてしまう。
まぁ、なんとなく雰囲気が伝われば幸いである。リベンジできたかなぁ?...まぁいいか。
Nodejsの同期、非同期について【readFile/readFileSync/Promiseとか】
えーと最近はJavaScriptで開発することが多い。サーバー側ではNodeJSだし。ブラウザ側でもJavaScript使うし。 JavaScriptとJavaは無関係っていうウンチクネタもあるのだが…

![[改訂第4版]SQLポケットリファレンス](https://images-fe.ssl-images-amazon.com/images/I/518GTfGD0aL._SL160_.jpg "[改訂第4版]SQLポケットリファレンス")
- 作者: 朝井 淳
- 出版社/メーカー: 技術評論社
- 発売日: 2017/02/18
- メディア: 単行本(ソフトカバー)
投稿者プロフィール
-
システムエンジニア
喋れる言語:日本語、C言語、SQL、JavaScript