SQL分析関数(WINDOW関数)で複雑な集計をする話
 asai
asai本記事は前のブログに載せていた記事を再編集したものです。
最近(といっても2016年現在で)のSQLには分析関数という新しいジャンルの関数が存在する。できることは、集計関数とそれほど違いはないのだが、分析関数の特徴は、グループ化の方法や、集計する際の順番を関数毎に指定できるということ。
集計関数では、グループ化の具合は、SELECT命令のGROUP BYで指定する。集計するにあたり「処理順序は気にしない」。例えば、合計値を集計する時に、{1,2,3}といった集合があったとして、1+2+3=6という計算をしてもいいし、3+2+1=6としてもOK。
ところが、分析関数になるとそうもいかない。なぜなら、ソートして順に並んでいる状態で、先頭のデータとか、中央の値とか色々な集計というか、分析のための計算を行うことができるのである。
先ほどの例{1,2,3}で説明すると、昇順に並べた状態で、先頭なら1になるが、降順なら3となるであろう。
SQLで解説していくことにする。
まずは、テーブルを作ってみる。
CREATE TABLE test_analyze (
val INTEGER
);
INSERT INTO test_analyze VALUES(1);
INSERT INTO test_analyze VALUES(2);
INSERT INTO test_analyze VALUES(3);
SELECT * FROM test_analyze;
val
----
1
2
3
先頭のデータを取得する分析関数は、FIRST_VALUEである。分析関数を使用するにあたっては「OVER句が必要になる」。OVER句は従来からある集計関数では必要のないものである。OVER句では計算の順序を指定する。指定方法は、ORDER BYでの列指定となる。ORDER BYのやり方は、SELECT命令でソート方法を指定することと同じ感覚でできる。ASC、DESCでソート方法を変更可能である。
では、やってみよう。まずは、昇順で並べて、先頭データを参照してみる。
SELECT val, FIRST_VALUE(val) OVER (ORDER BY val ASC) FV
FROM test_analyze
val FV
---- ----
1 1
2 1
3 1
昇順で並べているから、先頭データは最小値になる。1,2,3のうち最初の1が計算される。
では、降順にしたら、3が計算されるのであろうか。やってみよう。
SELECT val, FIRST_VALUE(val) OVER (ORDER BY val DESC) FV
FROM test_analyze
val FV
---- ----
1 3
2 3
3 3
なりました。
FIRST_VALUEは「グループの先頭データを取得できる分析関数」であることがわかった。
ちょっと待て、GROUP BYしていないからグループなんてないのでは?
そうです。SELECT命令と同じように、グループ化する必要がなければ、グループ化の方法を省略することができる。省略した場合は、全体が一つのグループとみなされる。
分析関数でのグループ化は、PARTITION BY句で指定する。GROUP BYではないので、注意したいところ。PARTITION BYを省略した場合は、全体が一つのグループになる。
作成した例が良くなかったので、PARTITION BYの例は、また後でやることにしよう。
FIRST_VALUEは先頭だが、LAST_VALUEというのもある。こちらは、末尾を参照することができるのだが、ちょっと曲者です。まぁ、やってみましょうか。
SELECT val, FIRST_VALUE(val) OVER (ORDER BY val ASC) FV,
LAST_VALUE(val) OVER (ORDER BY val ASC) LV
FROM test_analyze
val FV LV
---- ---- ----
1 1 1
2 1 2
3 1 3
昇順ソートなので、FVは1、LVは3になってくれると思ったのだが…
その行と同じ値になっちゃっている。これは?
と最初は、思うと思います。普通に考えれば、3になってくれることを期待する。
「どうしてか」というと、分析関数に計算を依頼する際、デフォルトでは、SELECT命令で計算を行っているカレントの行
までが、渡されるようになっているから。つまり、val=1の行を処理している際は、集合{1}が分析関数に渡される。次の行val=2の時点では、{1,2}となり、さらに、3では{1,2,3}になる。
FIRST_VALUEでは、先頭しか参照しないので良かったが、LAST_VALUEは末尾になる。分析関数に与える集合が、その行を処理している中間結果となるため、末尾のデータと言っても、最終結果での末尾とは一致しない。
分析関数に与える集合をどの範囲までにするかを変更することができる。
デフォルトでは、次のような指定になっている。
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW FOLLOWING)
「カレント行まで」のところを「全部」に変更すれば、最終結果での末尾を参照することが可能になるはず。
やってみよう。
SELECT val, FIRST_VALUE(val) OVER (ORDER BY val ASC) FV,
LAST_VALUE(val) OVER (ORDER BY val ASC
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LV
FROM test_analyze
val FV LV
---- ---- ----
1 1 3
2 1 3
3 1 3
できた。
「デフォルトでカレント行まで」となっているのは、単にパフォーマンス的に有利だから。先頭データだけを参照するのであれば、カレント行より上のデータがわかれば良いので。並列処理でパイプライン的に処理することも可能と思われる。
![[改訂第4版]SQLポケットリファレンス](https://m.media-amazon.com/images/I/51o-wRLjMdL._SL500_.jpg)
NTH_VALUE
Oracle限定になってしまうが、「任意の位置のデータ」を参照することも可能である。NTH_VALUEには、引数で何番目の位置にあるデータが欲しいのかを指定する。
NTH_VALUE(val,1) なら FIRST_VALUE(val)と同じことになる。
以下は、2番目の位置にあるデータを参照する例である。
SELECT val, FIRST_VALUE(val) OVER (ORDER BY val ASC) FV
NTH_VALUE(val, 2) OVER (ORDER BY val ASC
RANGE BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING) SV,
LAST_VALUE(val) OVER (ORDER BY val ASC
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LV
FROM test_analyze
val FV SV LV
---- ---- ---- ----
1 1 2 3
2 1 2 3
3 1 2 3
LAST_VALUEと同様に、カレント行より後に参照したい場所がある場合に備え、範囲を指定する必要がある。「1 FOLLOWING」を指定して、カレント行から1行後までを「分析関数に与える範囲」としている点に着目して欲しい。
LAGとLEAD
NTH_VALUEでは、集合の「どの位置にあるデータなのかを絶対値で指定」しなければならなかった。LAG、LEADを使うことで、カレント行からの「相対位置指定」が可能となる。
LAGは、前方への参照、LEADは、後方への参照となる。NTH_VALUEと同様に、位置指定のための引数を与える必要がある。
以下の例を見て頂ければ、すんなりと理解できると思われる。
SELECT val, LAG(val,1) OVER (ORDER BY val ASC) LAG,
LEAD(val, 1) OVER (ORDER BY val ASC) LEAD
FROM test_analyze
val LAG LEAD
---- ---- ----
1 null 2
2 1 3
3 2 null
LAGでは、一つ前のレコードの値。LEADでは、一つ後のレコードの値を参照できます。
いやはや、これは便利ですよ。例えば、年間の実績値を集計して画面表示していたとしましょう。
年 実績値
2013 32400
2014 33500
2015 34200
前年比を横に計算してよ、という要望は多くあるでしょう。
SELECT 年, 実績値, LAG(実績値, 1) OVER (ORDER BY 年) 前年,
ROUND(実績値 / LAG(実績値, 1) OVER (ORDER BY 年) * 100,2) 前年比
FROM 実績集計
年 実績値 前年 前年比
------ ------ ------ ------
2013 32400 null null
2014 33500 32400 103.4
2015 34200 33500 102.09
なるほどこれは便利じゃない?。
他にも分析関数はあるので紹介していこう。
ROW_NUMBER
ROW_NUMBERは、OVER句を必要とする分析関数となる。
OracleのROWNUMは、WHERE句を処理する際に割り当てられるため、ORDER BYでソートされた順にはならない、といったことは結構有名である。
なので、ソートした結果で連番としたい場合や、行制限をかけたい場合には、一度サブクエリを作ってやらないといけなかったりして不便であった。
というわけで、ROW_NUMBERは「ソートした結果で行制限を行う」際によく使用されるのだが、実際は分析関数であるので、その他の用途でも、結構便利に使えるわけである。
ROW_NUMBERの機能は、引数で与えられた集合の個数+1を計算して戻すだけである。集合を明示的に引数で指定する必要はないので、ROW_NUMBER関数の引数は存在しない。
早速やってみるのだが、その前に、サンプルのテーブルを作成しよう。
CREATE TABLE test_analyze2 (
val INTEGER
);
INSERT INTO test_analyze2 VALUES(1);
INSERT INTO test_analyze2 VALUES(2);
INSERT INTO test_analyze2 VALUES(3);
INSERT INTO test_analyze2 VALUES(3);
INSERT INTO test_analyze2 VALUES(4);
SELECT * FROM test_analyze2;
val
----
1
2
3
3
4
サンプルができたので早速、ROW_NUMBERで順番を計算してみよう。
SELECT val, ROW_NUMBER() OVER (ORDER BY val ASC) NO
FROM test_analyze2
val NO
---- ----
1 1 {1}
2 2 {1,2}
3 3 {1,2,3}
3 4 {1,2,3,3}
4 5 {1,2,3,3,4}
{}で囲まれている数値は、引数で渡される集合を表現している。実際のクエリの結果には出現しないものなので、注意して欲しい。同時に、集合の要素数と一致することを理解して欲しい。
番号は、ORDER BYで指定された順序に従って振られていく。ASCをDESCに変更すると違った結果になってくる。
SELECT val, ROW_NUMBER() OVER (ORDER BY val DESC) NO
FROM test_analyze2
val NO
---- ----
4 1 {4}
3 2 {4,3}
3 3 {4,3,3}
2 4 {4,3,3,2}
1 5 {4,3,3,2,1}
集合の個数を計算することに変化はないが、要素の並びが降順となっていることに注目して欲しい。SELECT命令にORDER BYを付けていないので、全体のソート順もOracleの都合の良いように降順で出力されるようになった。
RANKとDENSE_RANK
RANKとDENSE_RANKも分析関数である。ROW_NUMBERは、順に連番を振っていくものだが、RANK、DENSE_RANKは順位を計算することができるというシロモノ。
連番と順位はどう違うかと申しますと、連番は、重なる番号が出現しないことに対して、順位は、同じ数値のものが、同じ順位になる、という点。
{1,2,3,3,4}とういう集合を例にして解説しているわけだが、この集合の中には数値3が二つ重複してある。数値が小さい方が優秀ということで話を進めると、1の順位が1位、2の順位が2。3の順位は、両方とも3になる。次の4はというと、ふた通りの考え方があるので、ちょっと後回し。
まずは、ROW_NUMBERとRANK関数を使って行番号と順位を比較してみよう。
SELECT val, ROW_NUMBER() OVER (ORDER BY val ASC) NO,
RANK() OVER (ORDER BY val ASC) RANK
FROM test_analyze2
val NO RANK
---- ---- ----
1 1 1 {1}
2 2 2 {1,2}
3 3 3 {1,2,3}
3 4 3 {1,2,3,3}
4 5 5 {1,2,3,3,4}
ROW_NUMBERは、集合の要素数を計算する。一方、RANK関数は、カレント行の値より前の順位となる要素数を計算して、その値に+1した数値を戻す。
最初の3の行では、{1,2,3}が集合として関数に渡り、3より順位が高い1と2の二つがあることがわかる。2+1を計算して3が結果として戻される。
次の3の行では、{1,2,3,3}が集合として関数に渡り、3より順位が高い1と2の二つがあることがわかる。2+1を計算して3が結果として戻される。
これで、データ3の順位はどちらも3位となリ、ROW_NUMBERとの差が発生する。
DENSE_RANK
ここで、後回しにしていた、次の4まで考えてみよう。3については、同値の行が2行あるので「どちらも3位になる」ことがわかった。
次の4の行では、{1,2,3,3,4}が集合として関数に渡り、4より順位が高い1,2,3,3の4つがあることがわかる。4+1を計算して5が結果として戻される。
3位の次だから4位とはならず「同値であった行数分だけ順位が飛ぶ」のがRANK関数の考え方。順位が飛んでしまう現象を「ギャップ」と呼ぶこともある。
RANK関数ではなく、DENSE_RANK関数を使うと少し違った様子になる。やってみよう。
SELECT val, ROW_NUMBER() OVER (ORDER BY val ASC) NO,
RANK() OVER (ORDER BY val ASC) RANK,
DENSE_RANK() OVER (ORDER BY val ASC) DRNK
FROM test_analyze2
val NO RANK DRNK
---- ---- ---- ----
1 1 1 1 {1}
2 2 2 2 {1,2}
3 3 3 3 {1,2,3}
3 4 3 3 {1,2,3}
4 5 5 4 {1,2,3,4}
DENSE_RANKでも、より順位が高い要素の数+1を計算する。異なるのは、集合から重複が取り除かれている点。つまり、DISTINCTされた状態で個数を計算するということ。なので、DENSE_RANKでは3位の次だから4位となり「同値である行があっても順位は飛ばない」ギャップが発生しない。
NTILE
さて、分析関数を使うことで、順位付けすることが簡単にできることがわかって頂けたかと思う。
分析関数が存在しなかった時代では、サブクエリを使って行番号や順位を計算していた。サブクエリとすると、SELECT命令が長くて複雑なものとなりやすい。分析関数を使えば、サブクエリよりも簡潔に分かりやすく記述できる。是非とも有益に使っていきたいものである。
サブクエリでなく、ユーザー定義関数を作ってしまう、という手もあり、自分でも結構関数を作ってきた。しかし、関数を作る際には、どうしても、スカラ値を返さなくてはならず、なんか面倒なことになりがち。分析関数で済むのなら、そっちの方が楽。
単純な順位付けなら、RANK関数で十分かも知れない。しかし、データ分析を実際にやろうとすると、データが大量にある場合などは、4つくらいのグループに分けて全体の傾向をつかみたい、ということもあるかと思う。
NTILEを使用すれば、そう言った順位付けを行うことが可能となる。
一つの例として、ヒストグラムを計算する際のSQLを例にしてみたい。ヒストグラムっていうのは、以下のようなデータの分布状態を視覚化したグラフ。デジイチユーザなら見たことがあるはず。
カメラのしくみ ヒストグラム
昨日、デジカメで撮影したデータを持って、カメラ屋さんに行き、プリントしてきた。フィルム時代はカメラ屋に持って行って、現像してもらわないといけないから、撮影後は…

デジタルカメラの場合は、R,G,Bの階調データをそれぞれの色で3つのグラフで表示したりする。階調も256くらいあるので、例としてはデータが大き過ぎる。なので、白黒で8階調ということにしよう。
8階調なので、数値は0〜7までの値となる。画素数は4x4=16個にしようか。
0 1 0 4
0 1 7 0
6 2 7 1
0 3 7 2
こんな感じの画像データがあったとする。画像に直すと、どうなるかちょっとよく分からないが、まぁなんとなくわかるでしょう。
実際のテーブルには、以下のような感じで行を作った。
SELECT * FROM test_analyze3
val
----
0
1
0
4
0
1
7
0
6
以下略
集計を行うにあたっては、ピクセルの位置は関係ないので、ピクセルに出力している階調データのみを行のデータとして記録しているだけの単純な構造にした。
ここから、階調0を出力しているデータの個数、階調1を出力している個数、階調2と、順に7まで集計すれば、ヒストグラムを表示することができる。数の集計なので、COUNT使って、GROUP BYすればOKかも。まぁ、そうですね。分析関数使うまでもないか。
SELECT val X, COUNT(val) Y
FROM test_analyze3
GROUP BY val
ORDER BY val
X Y
--------
0 5
1 3
2 2
3 1
4 1
6 1
7 3
これを、そのままグラフにすると、以下のようになる。
5 *
4 *
3 * * *
2 * * * *
1 * * * * * * *
0 1 2 3 4 5 6 7
テキストで作成したのでショボイが、なんとなく、ヒストグラムっぽいでしょ?
しかし、分析関数使ってませんね。普通にGROUP BYとCOUNTで済んでしまった。まぁ、SQLの潜在能力を「思い知らされただけ」っていう話もあるが。そうは言っても、分析関数である。
ヒストグラムを表示すると言っても、実際は、8階調っていうことはないわけで、フルカラーを表現するには、24ビット整数の精度くらいは必要、実際はもっと大きい数値になる。さらに、画面の制約があるので幅は100ドットくらいでグラフを表示したい…
で、分析関数を使えば、そう言ったことに柔軟に対応できるようになるのである。
ここで、ビューを作成する。一度は集計処理はしないといけないので、そのためのビューを定義してしまう。
CREATE VIEW v_test_analyze3 AS
SELECT val X, COUNT(val) Y
FROM test_analyze3
GROUP BY val
SELECT * FROM v_test_analyze3 ORDER BY X
X Y
---- ----
0 5
1 3
2 2
3 1
4 1
6 1
7 3
前のクエリをそのままビューにしただけなので、結果も変わらない。このビューの結果を元にさらに集計していく。
まず、画面に収めるため、Xが最大7であるところを半分の3にしてみたい。8階調であるところを、半分の4にしたいのである。そうすれば、小さい画面でもヒストグラムを表示できる。
いろいろなやり方はあると思うが、分析関数のNTILEを使ってやってみることにする(やっと出てきました分析関数)。
NTILEには、グループをいくつのグループに分割するのかを引数で指定できる。現段階での課題は、4つのグループに分割して、ヒストグラムを表示させたいので、NTILEの引数には4を指定する。
NTILEで分割したグループは「バケット」と呼ばれる。
SELECT X, Y, NTILE(4) OVER (ORDER BY X ASC) BUGT
FROM v_test_analyze3
ORDER BY X
X Y BUGT
---- ---- ----
0 5 1
1 3 1
2 2 2
3 1 2
4 1 3
6 1 3
7 3 4
BUGTが1となっている部分が、1のバゲットに含まれているデータ行になる。同様に2なら2のバゲットと分割数に指定した4まで続く。
この段階では、全体を4つのバゲットに分割して連番を振っただけに過ぎない。BUGTの列がその連番になっていると理解して欲しい。
前回の8階調ヒストグラムでは、X毎にデータの個数を計算したのだが、今回はこれを、BUGT毎に計算するのである。Yの値は、バゲット内のデータを合計する。BUGTは4分割したのだから、4階調に変換できるはず。
SELECT BUGT - 1 X, SUM(Y) Y
FROM (SELECT Y, NTILE(4) OVER (ORDER BY X ASC) BUGT
FROM v_test_analyze3) SUB
GROUP BY SUB.BUGT
ORDER BY X
X Y
---- ----
0 8
1 3
2 2
3 3
グラフにしたら
8 *
7 *
6 *
5 *
4 *
3 * * *
2 * * * *
1 * * * *
0 1 2 3
こうなる。前の8階調のグラフと比較してみる。
5 *
4 *
3 * * *
2 * * * *
1 * * * * * * *
0 1 2 3 4 5 6 7
なるほど、Xが0と1がバゲット0なので、Yの合計がバゲット0の数値8になっている。Xが2と3でバゲット1だから、2+1で3なのか。ちなみに、グラフの*の数はどちらも画素数の16個である。
なかなか良さそうではある、がしかし。
階調5のデータは0件なので、X={4,5}のバゲットとX={6,7}のバゲットが怪しい感じになっている。ちゃんとしたヒストグラムにしたい時は、5のところに0が入ってこないといけないことがわかった。まぁ、サンプルなので目をつむってもらうとしよう。
ヒストグラムの例を解説してみたのだが、難しい例になってしまったかも知れない。
「アンケート結果の年齢を年代別に集計したい」といった用途でNTILEを使える。
PERCENT_RANK
ここまで分析関数を解説してきたが、一度振り返ってみよう。
分析関数は「ウインドウ関数」と呼ばれる場合もある。レガシーな集計(COUNTとかSUMとか)とは違い、かなり色々なことができるように拡張されている、結構ハイテク(そうでもないか)な関数なことがわかる。
しかし「WINDOWって何」といったことを本ブログで解説していない気もする…LEADのところで少しやったか。
集計関数に引き渡す集合の範囲を決めるのがWINDOW。
それはさて置き。
SQLポケリにも分析関数を書いてはあるものの、何せ、いまいち「バラバラで決まっていない感」」があったので、見送っていた機能なのである。
最近になって、「やっぱり便利なんじゃない分析関数」ということで、このブログに"セコセコ"記事をアップしている次第である。で、今回は、PERCENT_RANKである。
PERCENT_RANK
RANKとDENSE_RANKは「順位」を整数値で計算してくれる関数であった。
「しかし」である。
唐突に「あなたの順位は、54位でした」と言われても、全体数がわからなければ、成績が良いのか悪いのか、中間くらいなのか、よくわかりませんよね。
全体で1000のうちの54位なら、まぁ上位の方だけれども、全体で100なら「中くらいの成績」でしかないわけである(一人中の一人だから1位と言われても…)。
そういった場合は、「パーセントで順位を示してあげる」ということをするわけなのだ!(うっ、なんか偉そう)。
パーセントなら、全体が100であることは「世界中で決定」しているので、50%ならちょうど中間だし、10%位なら、ベスト10入り。90%とかだとお尻の方、といった判断が簡単にできる。
「PERCENT_RANK」を使えば、全体で何個中の何位といった「パーセンテージ」で順位を計算してくれる。やってみよう。
SELECT val, PERCENT_RANK() OVER (ORDER BY val ASC) PRANK
FROM test_analyze2
val PRANK
---- -----
1 0
2 0.25
3 0.5
3 0.5
4 1
PERCENT_RANKの計算結果は、パーセンテージと言っても0〜100の数値ではなく、0〜1.0となる。本当に百分率(単位を%)にしたければ、100を掛け算すれば良い。
一番成績が優秀なデータは、順位0.0となる。逆に、一番お尻のデータは、1.0である。
ここでふと思った、1件しかデータがなかったら?0.0だろうか、1.0かも?
やってみた。
SELECT PERCENT_RANK() OVER (ORDER BY dummy ASC) PRANK FROM DUAL
PRANK
-----
0
どうやら、0になる。
そうか、バッチリ理解できた!
とはならないと思うので、もう少し解説してみたい。
PERCENT_RANKとRANKの両方を計算させてみた。
横っちょに集合と、計算式も書いてある。
SELECT val,
PERCENT_RANK() OVER (ORDER BY val ASC) PRANK,
RANK() OVER (ORDER BY val ASC) RANK
FROM test_analyze2
val PRANK RANK
---- ----- ----
1 0 1 {1} 0/4 = 0
2 0.25 2 {1,2} 1/4 = 0.25
3 0.5 3 {1,2,3} 2/4 = 0.5
3 0.5 3 {1,2,3,3} 2/4 = 0.5
4 1 5 {1,2,3,3,4} 4/4 = 1.0
RANKの場合は「全体の」データの個数を気にしなくてもよかったことに対して、PERCENT_RANKでは「全体の個数が必要」になってくる。そう、全体で1000あるのか、100なのか、といったことなのである。
まぁ、落ち着いて、1レコード毎に見ていこう。
最初の行は、値1である。このデータの順位は、最高位なのだが、PERCENT_RANKでの計算式は以下のようになる。
カレント行の値からRANKで順位を計算 - 1 / (全体のデータ数 - 1)
RANK関数では、集合から要素数を計算すればよかったのに対して、PERCENT_RANKでは、事前に全体のデータ数が必要になってくるのが最大の違い。
この例での全体のデータ数は、5になる。5レコードあるからね。これは間違いない。割り算の分母になる数値は-1しているから、4になる。5-1で4。
分子の方はというと、val=1のレコードでは、1-1=0になり、0/4で0になる。そう、一番優秀なのが0になる。
次に、val=2のレコードは、2-1=1で、1/4で0.25。
さらに、val=3は、3-1=2で、2/4で0.5。
最後は、val=4は、4/4で1.0。ビリは1.0。
どうだろうか。
まぁ、難しいことは置いといて、順位を総数に関係なく表現できるのが、PERSENT_RANKということで理解していただければ良いと思う。
データ分析をするにあたっては、尺度というか、基準というか、「全体のうちのどのくらいの位置にあるのか」ということが重要になってくると思う。パーセンテージにすれば、0から100までの数値に換算されるわけで、数量を把握するためには非常に便利な訳である。
PERCENT_RANKを使えば、パーセンテージで順位を計算してくれるので、単位変換しなくてもいいので、楽チン。くらいに覚えておくと良いであろう。「単位を揃える」っていう基本的なことなのかも知れない。
えーと、なんか偉そうになってしまった。スミマセン。
PERCENTTILE
ここからは、PERCENTILEである。パーセンタイル。あまり聞かない単語ではある。ちょっと検索してみたら、母子手帳にはパーセンタイルでグラフが載っているらしい。ふーん。ということは結構メジャーなものなのか。
前回紹介した、PERCENT_RANKは順位をパーセンテージで計算しました、っていうだけなので、パーセンタイルとはちょっと違う気もしないでもないが、同じかも?
どうも、順番に並べ替えて、パーセンテージでそのデータの位置を示したもの。というのがパーセンタイルらしいが…
まさに、PERCENT_RANKで計算できるような感じがするが。
分析関数としては、PERCENTILE_CONTとPERCENTILE_DISCの二つがある。どちらもパーセンタイル値を計算できるようなのだが、使い方が他の分析関数と比べて微妙に違う。
まず、OVER句ではなく、WITHIN GROUPでソート順を指定しないといけない。OVER句も付けることは可能ではあるが、PARTITION BYしか記述できない。さらに、関数に引数が必要なのである。PERCENT_RANKでは必要なかったのに… どうも勝手が違うなぁ、と思っていたら「やっぱり勘違い」していた。
PERCENTILE_CONT関数は、パーセンタイル値を計算してくれるのではなく、パーセンタイル値を引数で与えると、元の値が戻されるという関数なのだ。要は、PERCENT_RANKの逆関数みたいなものか。
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val)
とすると、val列でソートして計算したパーセンタイル値0.5に相当するval列の値を戻してくれる。
パーセンタイル値は0〜1.0の範囲外になることはない(試しに入れてみたらエラーになった)。
引数で0を与えれば、PERCENTILE_CONTは一番優秀とされたvalの値を戻す。1を与えれば逆に最低の成績を戻す。0.5ならちょうど真ん中の値を戻してくれる。という理屈である。
0.5を与えた際に戻ってくる値を「中央値」と呼ぶ。データ分析をする上では、中央値という言葉をよく耳にすると思う。
PERCENTILE_CONTの引数に0.5を入れることで中央値を計算できる。と覚えておこう。
SELECT val, PERCENT_RANK() OVER (ORDER BY val) RANK
FROM test_analyze2
val RANK
---- ----
1 0
2 0.25
3 0.5
3 0.5
4 1
SELECT
PERCENTILE_CONT(0) WITHIN GROUP (ORDER BY val) hi,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) mid,
PERCENTILE_CONT(1) WITHIN GROUP (ORDER BY val) lo
FROM test_analyze2
hi mid lo
---- ---- ----
1 3 4
分析関数percentile_cont 中央値でノイズ除去
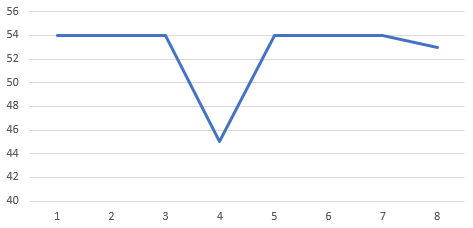
というわけで前回からの続きである。 まずはデータを用意する。問題の部分を切り抜いてみた。 54 54 54 45 54 54 54 53 車速なので単位はkm/hと思われる。データの粒度は0…
なんとか値のまとめ
蛇足ながら、データ分析で使われる「なんとか値」をまとめてみたいと思う。
・最大値・最小値
まぁね。これは、わかるでしょう。SQLでは集計関数のMAXとMINで計算できる。
・合計値
集合のデータをすべて足し合わせた値。SQLではSUM。
・平均値
データの合計値を個数で割り算した値。SQLではAVGで計算可能。
・パーセンタイル値
あるデータのそれを含む集合の中での位置をパーセンテージで示した値。百分位。
SQLでは、PERCENT_RANKまたは、CUME_DISTで計算できる。
・中央値
パーセンタイル値が、0.5となるデータの値。集合の中でちょうど真ん中に位置するデータの値。
SQLでは、PERCENTILE_CONT、PERCENTILE_DISC、MEDIANで計算できる。
・最頻値
集合の中で、最も頻繁に出現する数値。
これは、専用の関数は存在しないか…
PERCENTILE_DISC と MEDIAN
中央値を計算するのに、PERCENTILE_CONTとPERCENTILE_DISC、さらにはMEDIANの3つが存在する。前の例では、PERCENTILE_CONTを使ったのだが、PERCENTILE_DISCの方が良かったかも知れない。PERCENTILE_CONTは補間された値を計算して戻す可能性がある。
MEDIANは、PERCENTILE_CONTの引数が0.5に固定された、いわばシンタックスシュガーな分析関数である。中央値の計算がしばしば行われるということの裏返しかも知れない。
真ん中?
PERCENTILE_CONTがどうやって補間をするのかを解説していこう。
そもそも、集合の中の真ん中って「いったいどこ」ということを考えていく。
補間の方法が集合全体の要素数が奇数か偶数かで変化する。
集合の要素数が、奇数のとき。例えば、以下の集合があったとして
{1,2,3,4,5}
真ん中の値って、3ですわな。
集合の要素数が、偶数のとき。例えば、以下の集合だと
{1,2,3,4}
真ん中って?
PERCENTILE_CONTでは、集合の全体数が奇数である場合と偶数である場合で、処理方法が異なる。奇数のときは、真ん中に対する値が存在するので、その値をそのまま戻す。
偶数のときは、真ん中に位置するふたつの値が存在するので、ふたつの値の真ん中を補間して戻す。
{1,[2,3],4}
[2,3]が真ん中のふたつの値になる。2と3の中間を線形補間して、2.5を戻す。
PERCENTILE_DISCでも奇数と偶数で処理が異なるのは同じではある。偶数の場合真ん中のふたつの値が存在することになるが、補間をせず、最初の値をそのまま戻す。
{1,[2,3],4}
[2,3]が真ん中のふたつの値になる。最初の値2を戻す。
サンプルを作って、検証してみよう。
CREATE TABLE test_analyze4 (
val INTEGER
);
INSERT INTO test_analyze4 VALUES(1);
INSERT INTO test_analyze4 VALUES(2);
INSERT INTO test_analyze4 VALUES(3);
INSERT INTO test_analyze4 VALUES(4);
SELECT
PERCENTILE_CONT(0.5) OVER (ORDER BY val) CONT,
PERCENTILE_DISC(0.5) OVER (ORDER BY val) DISC
FROM test_analyze4
CONT DISC
---- ----
2.5 2
-- もう一行作って奇数にしてみる
INSERT INTO test_analyze4 VALUES(5);
SELECT
PERCENTILE_CONT(0.5) OVER (ORDER BY val) CONT,
PERCENTILE_DISC(0.5) OVER (ORDER BY val) DISC
FROM test_analyze4;
CONT DISC
---- ----
3 3
ばっちり。
いかがでしたでしょうか。分析関数について過去のブログ記事から前半部分を再編集して掲載してみました(後半も作成予定です)。
SQLポケットリファレンスにも分析関数が掲載されています。こちらもよろしくお願いします。
投稿者プロフィール
-
システムエンジニア
喋れる言語:日本語、C言語、SQL、JavaScript




